Multi-agent AI gives every person on your team an LLM agent that talks, reacts and decides in a scenario you choose. The output: chemistry score, conflict zones, and per-person verdicts grounded in evidence quotes.
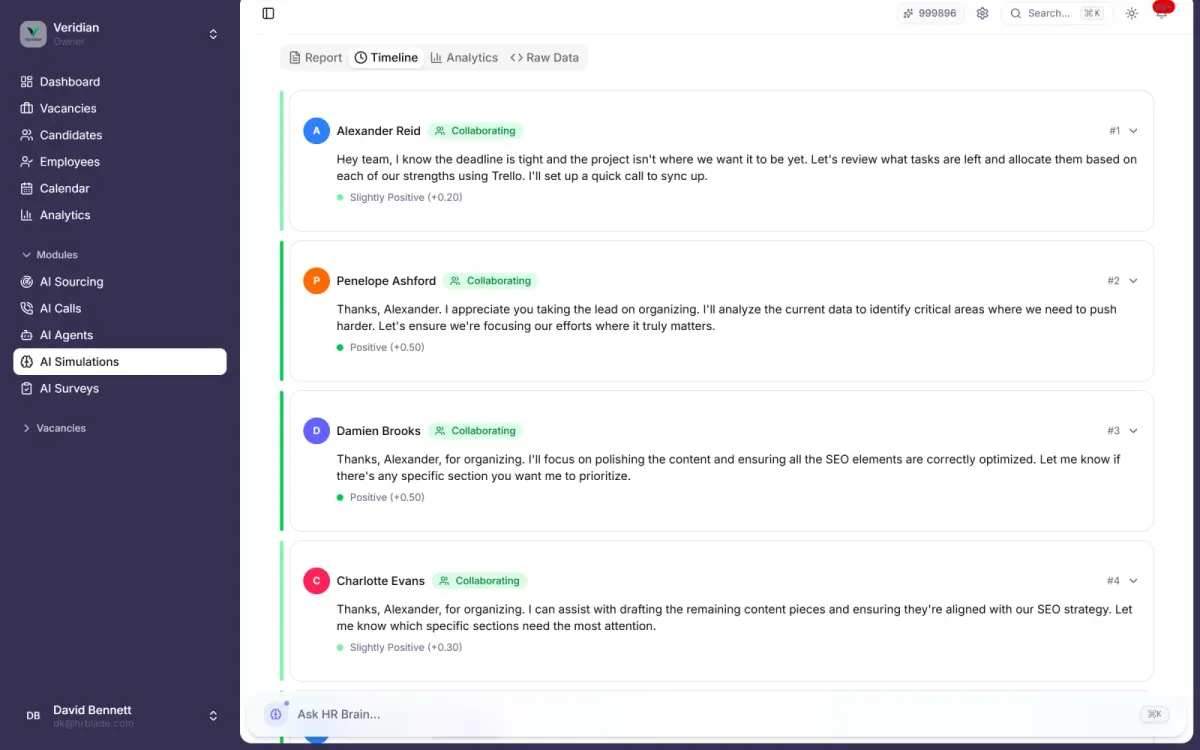
It's not a chatbot. Each participant becomes a character agent with their real Big Five profile, communication style, strengths and motivations. Drop them into a scenario — a team conflict, a stress deadline, a 90-day onboarding journey — and watch the dynamics play out turn by turn. Then HRBlade analyzes the dialogue and tells you what would actually happen.
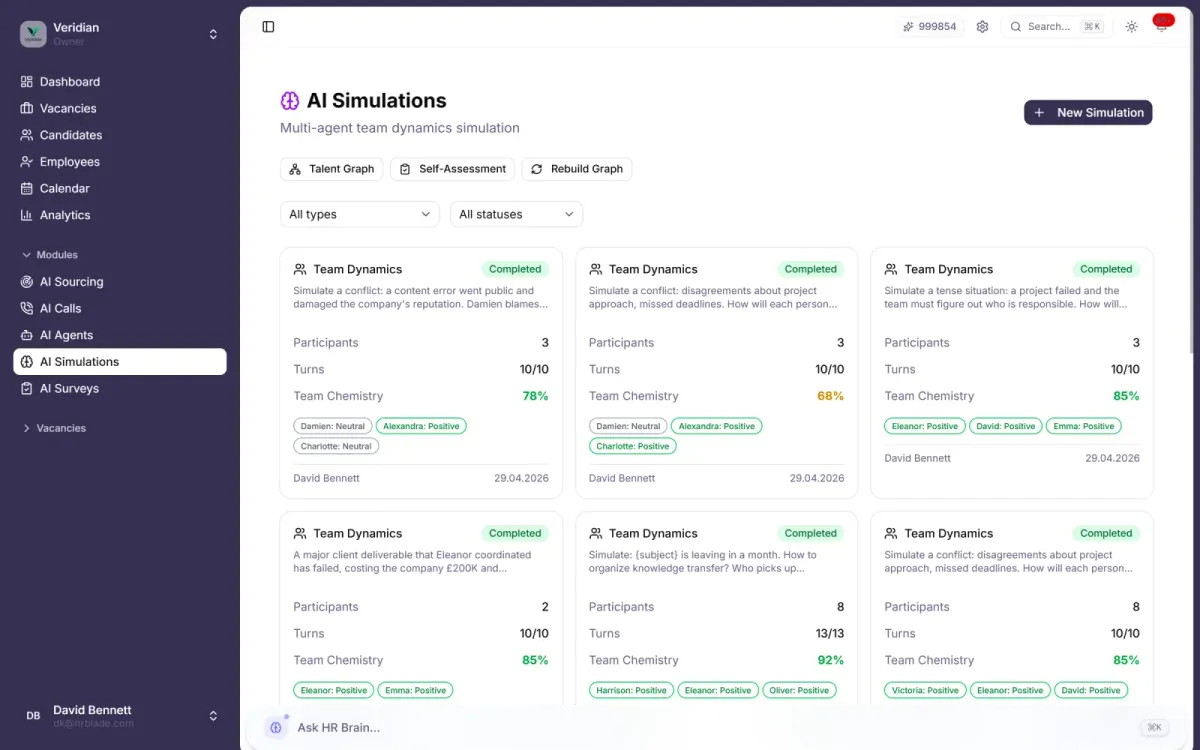
Will this candidate fit? Drop them into your existing team and watch chemistry, friction and collaboration emerge. Get a 0–100 chemistry score with breakdowns for communication, trust, conflict resolution and innovation.
Six checkpoints from Day 1 through Month 3. See the integration trajectory, retention prediction, and red flags that would normally only surface after offer-letter regret.
Run the same team with and without the candidate. The delta tells you the real effect on morale, productivity, conflict and innovation — quantified, not guessed.
Stress-test a reorg, a budget cut, a merger, a key person leaving. Describe the scenario in your own words; the simulation runs and reports.
Every recommendation cites the dialogue turns it came from. Strong Hire / Hire / Cautious / Pass — with the actual moments that drove the call.
Agents are seeded with each person's Big Five traits, communication style, and bio — pulled from interview transcripts, AI Surveys and assessments. Not generic personas.
Select who you're evaluating and the team they're joining. Profiles auto-load from candidate or employee records.
Team Compatibility, Onboarding, Leadership A/B, or describe your own situation in plain language.
About 15 turns of in-character dialogue and decisions. Each agent reads the conversation history and responds in voice — with sentiment, action, and internal thoughts.
Per-person recommendation with evidence quotes, conflict zones with severity ratings, team chemistry breakdown, and a 4–6 paragraph narrative report.
Source: HRBlade SimulationEngine spec
Source: HRBlade SimulationEngine spec
Source: HRBlade product
Before you make an offer, run the candidate against three of your top performers. If chemistry < 60 and conflict zones are high, you've just saved a year of dysfunction.
Will this engineer be a great EM? Run a Leadership A/B simulation. The delta on team morale and innovation is your answer.
Run the 90-day simulation on Day 1. If the trajectory dips at Week 2, you have time to course-correct before probation ends.
Merging two teams? Restructuring reporting lines? Run a Custom Scenario simulation and see who clashes, who emerges as bridge, who gets isolated.
It's grounded in each person's real psychometric profile, communication style and stated motivations — pulled from AI Surveys, interview transcripts and assessments. The dialogue isn't a transcript of what they will say; it's a high-fidelity model of how they tend to react. Treat verdicts as a structured second opinion, not a polygraph.
Catch flight risk, burnout, and quiet conflict — with evidence quotes from open-text responses.
Your talent database is a graph, not a list. Find hidden connections, skill gaps and internal-mobility paths.
Learns from your hiring history. Correlation between AI score and 6-month performance: r = 0.74.