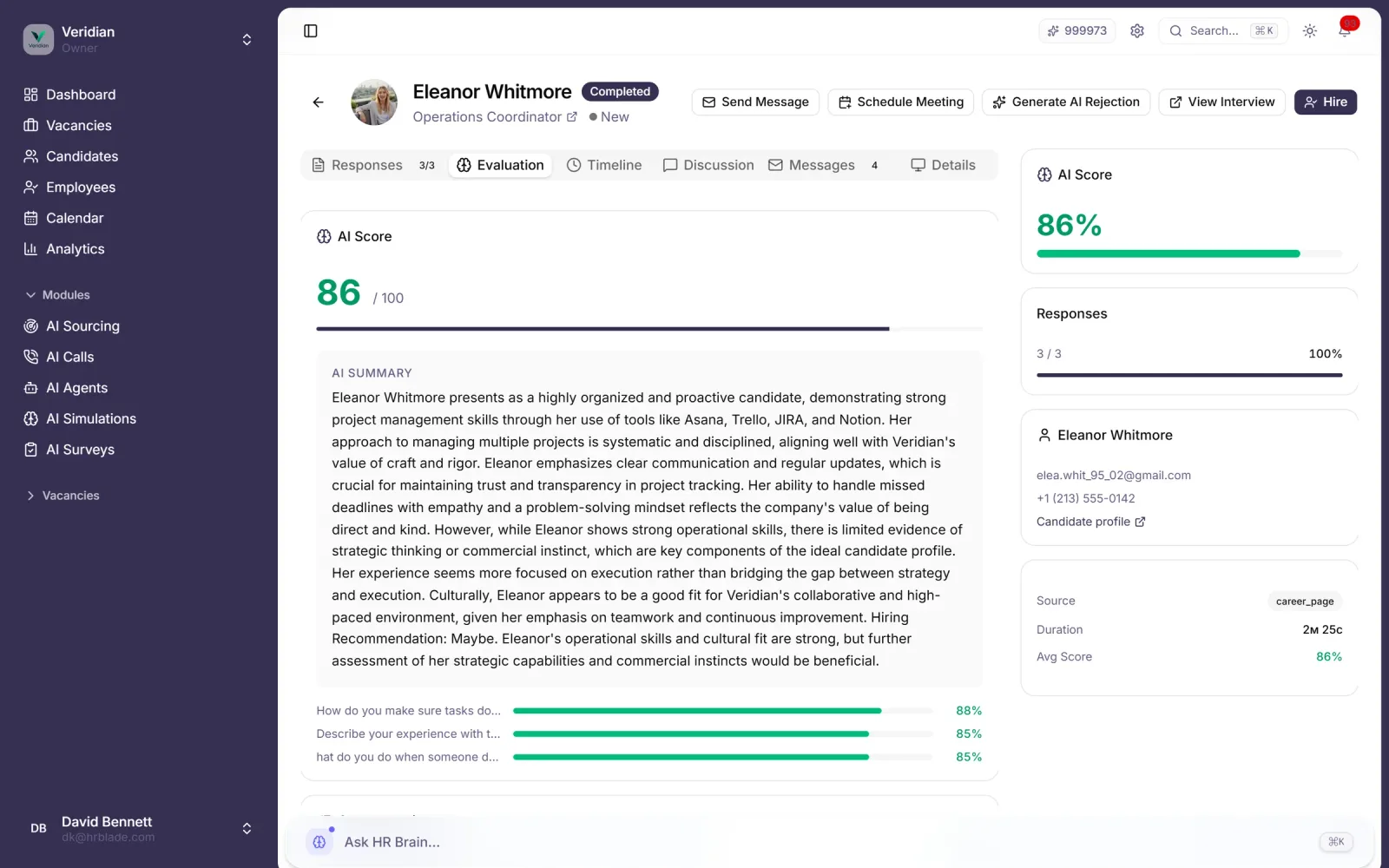
Multi-layer integrity engine flags AI-generated text, copy-paste from public answers, suspicious behavior and outsourced submissions — with 94% detection accuracy.
Start free trial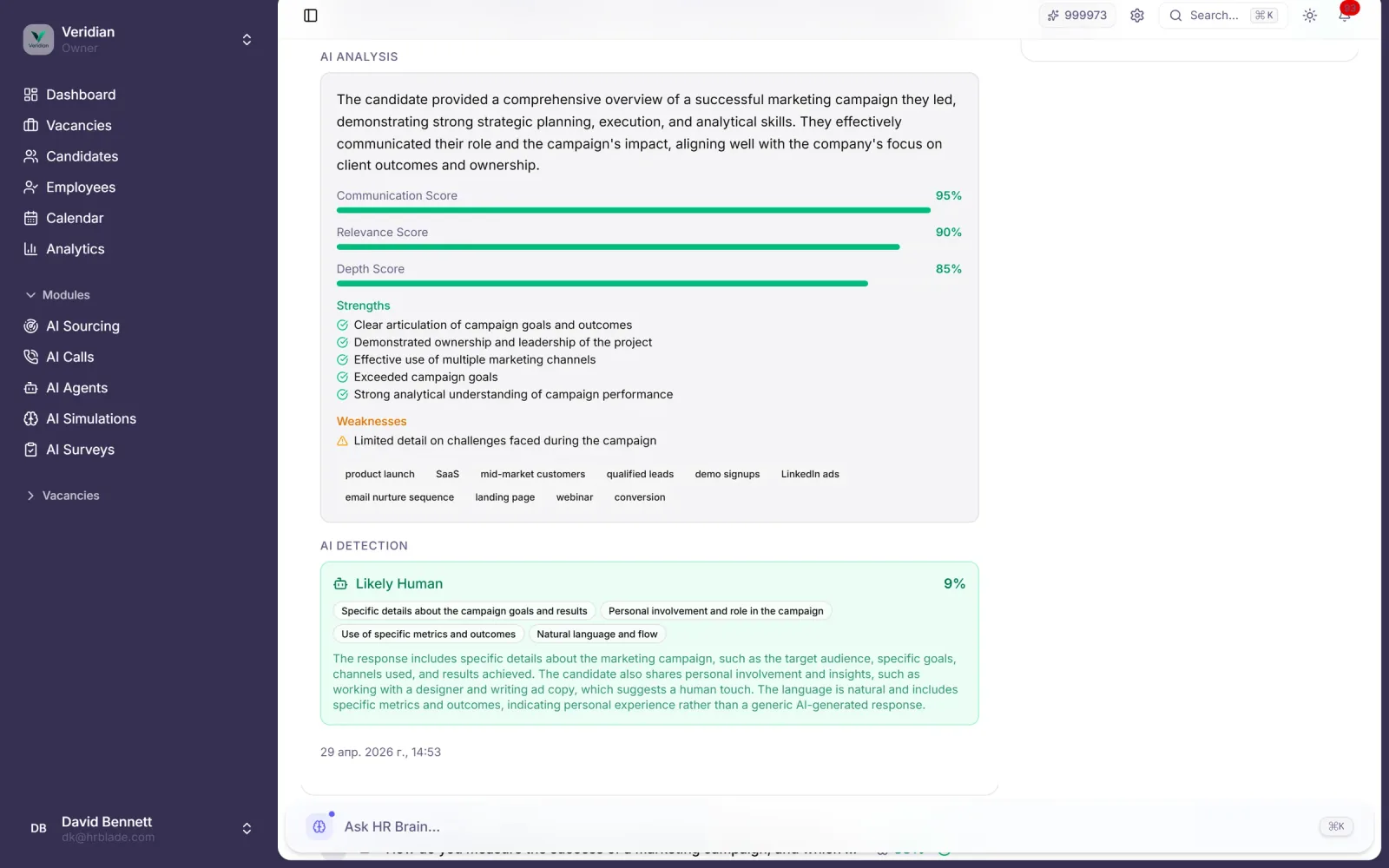
Anti-LLM classifier flags responses written by ChatGPT, Claude or Gemini across English, Spanish and German submissions.
Tab-switch detection during assessments, paste-frequency anomalies, time-on-question patterns, edit-history inspection.
Every flagged response includes the reasoning, source comparison and confidence score for the recruiter to review.